Modelo predictivo para la toma de decisiones en la gestión de insumos y medicamentos (página 2)
Conjunto de técnicas que se utilizan al diseñarse un sistema de información que reúne datos desde distintas partes, para agruparlos en una sola fuente. El proceso consiente en: Primero, extraer los datos desde sistemas informáticos, bases de datos, entre otros. Segundo, transformarlos a valores y formatos específicos. Y tercero, cargarlos en la base de datos o repositorio final.
2.4.10. Weka.
Es un software que ha sido desarrollado por la universidad de Waikato en Nueva Zelanda, bajo licencia GNU-GPL, consta de un conjunto de librerías JAVA para la extracción de conocimientos desde bases de datos, mediante las interfaces que ofrece o para embeberlos dentro de cualquier aplicación. "Soporta varias tareas estándar de minería de datos, especialmente, reprocesamiento de datos, clustering, clasificación, regresión, visualización, y selección." (Rodríguez y Díaz, 2009, p. 78).
2.5. Sistema de Variables y Operacionalización.
Proceso cuyo principal logro es identificar los indicadores que hacen observable, medibles y operativos los objetivos específicos del trabajo en estudio, para poder evaluar adecuadamente los resultados de la investigación. El sistema de variables y operacionalización constituye la base y el inicio del desarrollo de la solución tecnológica planteada. A partir de los indicadores establecidos se procede a elaborar los instrumentos de recolección de información.
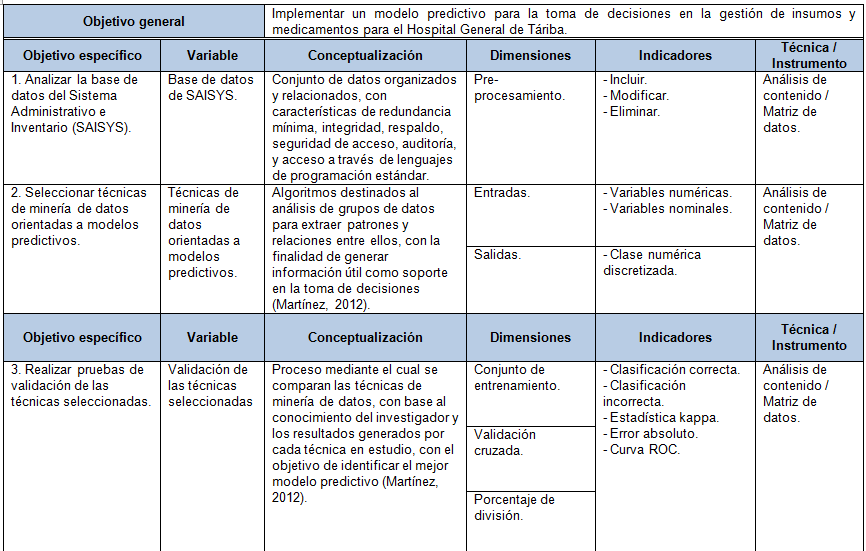
Tabla 2.1. Operacionalización de variables.

CAPÍTULO III
Marco metodológico
3.1. Contexto de la Investigación.
El propósito del presente estudio está orientado en una investigación aplicada, donde a través de la utilización de conocimientos en la práctica, se busca aplicarlos en la realidad para solucionar problemas de forma directa e inmediata, elabora productos para satisfacer necesidades. Esta investigación antes que el desarrollo de teorías, busca conocer para actuar, para construir y persigue en la mayoría de los casos el logro de objetivos en provecho de la sociedad.
El tipo de investigación de acuerdo al ambiente de estudio y las fuentes empleadas es mixta, donde participan factores de la investigación documental e investigación de campo. La investigación documental se alcanzó a través de fuentes utilizadas para elaborar el marco teórico y metodológico como libros, tesis, trabajos de grado, decretos, artículos científicos y documentos digitalizados. La investigación de campo se logró debido a que se emplearon herramientas para la recolección de datos desde la realidad donde sucedieron los hechos.
3.2. Nivel de Investigación.
La actual investigación se encuentra ubicada en el área de la ingeniería en tecnologías de información y comunicación, dentro de la línea de ingeniería de software de aplicación en el campo de los sistemas de apoyo a las decisiones gerenciales. El nivel de conocimiento de la investigación es proyectiva, la cual tiene como propósito la elaboración de una propuesta o modelo como solución a un problema o necesidad de tipo práctico.
El método utilizado en la investigación es la inducción, mediante el cual se empleó el razonamiento e inicia de hechos particulares aceptados como válidos, para obtener conclusiones cuya aplicación es de carácter general (Bernal, 2010). El método inductivo comienza con una recolección de datos, se categorizan las variables observadas, en ocasiones se hace énfasis en el hallazgo de variables críticas que permitan efectuar exploraciones sistemáticas, se establecen regularidades y relaciones entre los datos, para luego someterlos a prueba a partir de observaciones controladas y finalmente se puede obtener una estructura de generalizaciones relacionadas sistemáticamente que posibiliten elaborar una teoría.
3.3. Diseño de la Investigación.
Diseño mediante el cual a juicio de Hernández, Fernández y Baptista, (2010) se recoge la información necesaria para responder de forma concreta las preguntas de la investigación, además de cubrir los objetivos fijados, específicamente se refiere al plan o estrategia creada para obtener la información requerida. Si el diseño se realiza cuidadosamente, serán mayores las posibilidades de éxito para producir conocimiento como resultado final del estudio.
3.4. Población.
Son las personas u objetos que tienen relación directa con el caso en estudio, así lo afirma Tamayo (2010) es la totalidad de unidades o individuos que participan en el caso a ser estudiado. La población la determina el objetivo general de la investigación y en el presente estudio está representada por la base de datos de SAISYS, de donde a través del proceso KDD se extrajeron los datos relevantes que generaron información para la construcción del modelo predictivo, base fundamental en la realización de la solución tecnológica.
3.5. Técnicas e Instrumentos de Recolección de Datos.
Análisis de Contenido.
Proceso que estudia contenidos específicos de la investigación, de una manera objetiva y sistemática, para determinar información relevante inherente al caso de estudio (Hernández, et al., 2010). A través del análisis de contenido realizado en detalle, profundidad y exhaustividad, se obtiene un conocimiento deducido valido aplicado a un contexto, determinado por la capacidad de inferencia del analista, por lo tanto el rigor de la objetividad juega un rol fundamental en la ejecución de la presente técnica de recolección de datos.
En la presente investigación la técnica de análisis de contenido empleando el instrumento de matriz de datos, origino un factor primordial para el logro de varios objetivos específicos, debido que se utilizó para registrar, revisar y analizar información de los siguientes elementos del caso en estudio: En la base de datos de SAISYS, durante el proceso de seleccionar las técnicas de minería de datos orientadas a modelos predictivos y en el desarrollo de las pruebas de validación de las técnicas seleccionadas.
La Observación.
Técnica mediante la cual a través del uso de los sentidos, se capta directamente la realidad que rodea un caso de estudio. "Este método de recolección de datos consiste en el registro sistemático, válido y confiable de comportamientos y situaciones observables, a través de un conjunto de categorías y subcategorías." (Hernández, et al., 2010, p. 260). Datos que luego de analizarlos generan información valiosa para lograr los objetivos planteados en la investigación. Los pasos que debe tener la observación son:
1. Determinar el objeto que se va a observar.
2. Establecer los objetivos de la observación.
3. Determinar la forma con que se van a registrar los datos.
4. Observar cuidadosa y críticamente.
5. Registrar los datos observados.
6. Analizar e interpretar los datos.
7. Elaborar conclusiones.
En el presente estudio la técnica de la observación se
realizó a la herramienta informática desarrollada para la consulta
del modelo predictivo, los datos se registraron en un instrumento denominado
lista de cotejo, para posteriormente ser analizados y determinar si el proyecto
propuesto ofrece la información necesaria en el proceso de negocio, para
solucionar la problemática existente en la gestión de insumos
y medicamentos del Hospital General de Táriba.
3.6. Validez y Confiabilidad.
La validez de un instrumento está dada en si realmente evalúa
lo que se intenta medir. La misma está determinada por la sumatoria de
los resultados de la validez de contenido, validez de criterio y validez de
constructo. "La confiabilidad de un instrumento de medición se refiere
al grado en que su aplicación repetida al mismo individuo u objeto produce
resultados iguales." (Hernández, et al., 2010, p. 200). De acuerdo
con lo anterior, la confiabilidad indica que el instrumento no tiene errores,
por lo tanto sus resultados son vinculados y consistentes. La validez y la confiabilidad
representan la ausencia del azar.
3.7. Técnicas de Procesamiento y Análisis de Datos.
Una vez obtenida la información a través de los instrumentos de recolección de datos se procedió a codificarla, tabularla, analizarla y así obtener información relevante para el desarrollo de la investigación. Según Bernal (2010) consiste en procesar los datos (Dispersos, desordenados) conseguidos de la población en estudio, con la finalidad de generar datos (Agrupados y ordenados), a partir de los cuales se realiza el análisis según los objetivos y las preguntas de la investigación.

Figura 3.1. Procedimiento para el análisis de los datos.
Fuente: (Hernández, et al., 2010, p. 278). Adaptado por el autor.
Los datos obtenidos mediante el análisis de contenido y la observación se analizaron cuantitativamente a través de sistemas de información desarrollados para tal fin, la forma tradicional de hacerlo manualmente ha quedado relegada, en especial cuando hay un volumen considerable de datos. Por lo tanto la interpretación de los datos se efectuó por medio de sistemas de información, en la siguiente tabla se especifican los análisis y procedimientos realizados con cada sistema de información.
Tabla 3.1. Sistemas de información utilizados.
Sistema de información | Técnicas de análisis y procedimientos | ||
Weka. |
| ||
Excel – Calc. |
| ||
CAPÍTULO IV
Análisis e interpretación de resultados
Tabla 4.1. Simbología empleada en el capítulo.

4.1. Selección e Integración de los Datos.
Los datos se obtienen desde el sistema SAISYS, el cual guarda la información en un archivo de base de datos (Data Base File, dbf) que puede ser leído desde una hoja de cálculo como excel o calc, los registros a ser analizados son los comprendidos desde enero de 2.010 hasta diciembre de 2.015. La base de datos está conformada por una tabla maestro con 4.479 registros y una de transacciones con 81.119 registros.
4.2. Preparación de los Datos.
Proceso mediante el cual se procedió a revisar las hojas de cálculo de la tabla maestro y transacciones obtenidas en la fase anterior. La preparación de los datos consistió en realizar actividades de limpieza y pre-procesamiento, para corregir errores en el conjunto de datos seleccionados. Las acciones ejecutadas se presentan en la siguiente tabla.
Tabla 4.2. Matriz análisis de la base de datos de SAISYS.

4.3. Transformación.
Etapa del proceso KDD que permitió reducir y agrupar los datos. El resultado de la fase anterior se importó a MySQL y a través del lenguaje de programación PHP, se consolidaron todos los datos en un repositorio de información denominado master con 79.448 registros.
Tabla 4.3. Selección de las variables de estudio.

Descripción de las Variables No Nominales Seleccionadas.
id: Variable clave primaria del repositorio de información master, numero correlativo desde 1 hasta 79.448.
codigo: Contiene el código del producto, variable tipo carácter, sus valores fluctúan entre 10.001 y 90.322.
descripcion: Variable tipo carácter, almacena la descripción y especificaciones de cada insumo o medicamento.
unidad: Corresponde con la unidad de medida de los productos, entre otros presenta los siguientes valores: amp, fco, sbr, rollo, kit, bto y cja.
costo: Variable de valores numéricos continuos, sus valores oscilan entre 0 y 16.500, con una media de 318,33 y una desviación estándar de 1.261,86.
stockMin: Almacena la mínima provisión de cada insumo, valores numéricos no continuos que fluctúan entre 0 y 3.000, presentando una media de 130,64 y una desviación estándar de 336,86.
stockMax: Contiene la máxima provisión de cada producto, valores numéricos no continuos que oscilan entre 0 y 36.000, mostrando una media de 1.353,25 y una desviación estándar de 3.810,81.
fecha: Variable tipo carácter que guarda la fecha de la transacción por producto, para el estudio se utilizaron los datos correspondientes desde enero de 2.010 hasta diciembre de 2.015.
cantidad: Variable numérica entera, contiene la cantidad de cada insumo o medicamento por transacción, en el repositorio es la variable a predecir o dependiente, presenta una media de 339,84 y una desviación estándar de 945,40.
Descripción de las Variables Nominales Seleccionadas.
Tabla 4.4. Variable código del departamento por productos (dpto).
N° | Valor | Descripción | ||||
1 | 01 | Material médico. | ||||
2 | 02 | Medicamento. | ||||
3 | 03 | Instrumental. | ||||
4 | 04 | Odontología. | ||||
5 | 05 | Laboratorio. | ||||
6 | 06 | Papelería. | ||||
7 | 07 | Radiología. | ||||
8 | 08 | Mantenimiento. | ||||
9 | 09 | Nutrición | ||||
Tabla 4.5. Variable prioridad de adquisición (prioridad).
N° | Valor | Descripción | ||
1 | 1 | Alta. | ||
2 | 2 | Media. | ||
3 | 3 | Baja. | ||
Tabla 4.6. Variable necesidad de refrigeración
(refrigerado).
N° | Valor | Descripción | ||
1 | 1 | Si. | ||
2 | 2 | No. | ||
Tabla 4.7. Variable restricciones en almacenaje (almacenaje).
N° | Valor | Descripción | ||
1 | 1 | Si. | ||
2 | 2 | No. | ||
Tabla 4.8. Variable estatus del registro (estatus).
N° | Valor | Descripción | ||||
1 | 1 | Compra. | ||||
2 | 2 | Ajuste. | ||||
3 | 9 | Salida a servicio. | ||||
Tabla 4.9. Variable código del servicio destinatario (servicio).

Variable Discretizada: Se realizó la discretización de la variable dependiente cantidad, la cual se segmento en grupos múltiplos de 5, con el propósito de reducir la dispersión de los datos, proceso que se efectuó a través del lenguaje de programación PHP. En la siguiente tabla se detallan los factores que se tomaron en cuenta para seleccionar el tipo de rango en la discretización.
Tabla 4.10. Evaluación para determinar el tipo de rango.

Cierre: Para finalizar la etapa de transformación, con los datos disponibles se procedió a generar el documento arff, el cual es necesario para trabajar con la herramienta Weka, actividad realizada con el lenguaje de programación PHP.
4.4. Selección y Aplicación de Algoritmos de Minería de Datos.
Factores Determinantes en la Selección de las Técnicas de Minería de Datos.
Entrada – Variables numéricas, variables nominales: Las técnicas seleccionadas deben aceptar como datos de entrada números y valores nominales, para la construcción del modelo.
Salidas – Clase numérica discretizada: Es la clase a predecir, la cual es numérica segmentada en grupos múltiplos de 5, por lo tanto la técnica de minería de datos seleccionada debe procesar como resultado este tipo de salida, para realizar el modelo predictivo.
Tabla 4.11. Matriz selección de técnicas de minería de datos orientadas a modelos predictivos.

Breve Descripción de los Modelos Seleccionados.
Clustering: Técnica fundamentada en la segmentación de un grupo diverso de datos, en un conjunto de subgrupos (Clústeres) que presenta características similares.
J48: Clasificador para generar un árbol de decisión C4.5 podado o sin podar, se fundamenta en el concepto de entropía de la información.
JRip: Método que implementa un aprendizaje de regla proposicional, repite incrementalmente la poda para cortar la reducción de errores.
Naïve Bayes: Clasificador basado en el teorema de bayes, es rápido y poco complejo, constituye una técnica supervisada.
OneR: Técnica basada en reglas para la construcción y el uso de un clasificador 1R, es sencillo y rápido, utiliza para predecir el atributo con mínimo error.
Perceptrón multicapa: Es una red neuronal artificial, técnica que utiliza backpropagation para clasificar los casos. Los nodos de esta red son todos sigmoideo (Excepto cuando la clase es numérica, en cuyo caso los nodos de salida se convierten en unidades lineales de umbral).
REPTree: Árbol de decisión de aprendizaje rápido. Los valores perdidos se tratan mediante el fraccionamiento de las instancias correspondientes en trozos, es decir, como en C4.5.
Preprocesamiento con Weka.
Filtrado: Proceso mediante el cual se aplicó el filtro supervisado de atributos discretización (Discretize) al conjunto de datos, para discretizar valores numéricos no nominales, específicamente a los atributos: codigo, costo, stockMin y stockMax, pero los resultados obtenidos con y sin el filtro en los modelos, eran iguales, por tal motivo se decidió no utilizar en la investigación las derivaciones de la presente fase.
Eliminación: Utilizando la opción de preprocesado, filtro no supervisado de atributos para eliminar inútiles (RemoveUseless), con la finalidad de remover atributos constantes o que excedan el porcentaje máximo de varianza, se aplica solo a los atributos nominales. Para el análisis de los datos en estudio se estableció el umbral de la más alta varianza permitida en 30%, el resultado del proceso no elimino ninguno de los atributos en estudio.
Balanceo: A través de la opción de filtro supervisado de instancias volver a muestrear (Resample), se procedió a balancear la clase, con el objetivo de equilibrar los datos, pero los resultados obtenidos en los modelos luego de utilizar esta opción, no eran tan óptimos como sin emplear la presente herramienta, por lo tanto no se aplicó al conjunto de datos.
Opciones de Prueba Realizadas a cada Técnica Seleccionada.
Conjunto de entrenamiento: Con esta opción se construye el modelo con el 100% del conjunto de los datos disponibles, para luego hacer las pruebas sobre el mismo conjunto de datos.
Validación cruzada, 5 partes: Consiste en dividir en 5 segmentos los datos. Weka toma cada parte y construye el modelo con las partes restantes, para luego probar el modelo con la parte que tomo inicialmente y así sucesivamente repite el proceso con todos los segmentos.
Porcentaje de división, 70%: Opción de prueba que toma el 70% de los datos disponibles, para construir el modelo, y la prueba las realiza con el restante 30% de los datos.
Criterios a Evaluar.
Clasificación correcta: Corresponde al porcentaje de datos clasificados como aciertos durante la construcción del modelo predictivo, cuanto más próximo a 100% sea el valor resultante, el modelo es más efectivo, se considera un modelo valido cuando la clasificación correcta es superior al 70%. En la presente investigación el modelo se califica como aprobado si la clasificación correcta supera el 75%.
Clasificación incorrecta: Constituye el porcentaje de datos clasificados como desaciertos al momento de construir el modelo predictivo, Los modelos con clasificación incorrecta mayor o igual al 25% no son considerados válidos.
Estadística kappa: Según Corso (2009) mide la coincidencia de la predicción con la clase real. Sus valores están establecidos entre 0 y 1. Al respecto, mientras más se acerque el valor resultante a 0 no hay concordancia, entre tanto cuanto más cerca de 1 se encuentre existe mayor concordancia, En la presente investigación el modelo se califica como aprobado si la estadística kappa supera el 0,75 de fuerza de concordancia.
Tabla 4.12. Valoración estadística kappa.
Estadística kappa | Fuerza de concordancia |
< 0,00 | Pobre. |
0,00 – 0,20 | Leve. |
0,21 – 0,40 | Justa. |
0,41 – 0,60 | Moderada. |
0,61 – 0,80 | Sustancial. |
0,81 – 1 | Casi perfecta. |
Fuente: (Landis y Koch, 1977, p. 165)
Error absoluto: Representa la media de la magnitud de los errores individuales, así lo afirma Sánchez (2010). En consecuencia, es la diferencia entre el valor obtenido y el valor exacto.
Curva ROC: Es la representación gráfica de la sensibilidad frente a la especificidad, es decir, simboliza la razón de verdaderos positivos contra la razón de falsos negativos.
Coeficiente de correlación: Expresa la intensidad de la relación lineal entre dos variables, presenta valores entre -1 y 1, mientras más próximo sea el valor a 1 en cualquier dirección, más fuerte es la relación entre las dos variables, entre tanto, cuanto más cercano este de 0 el coeficiente de correlación, la relación será más débil.
Pruebas Realizadas a las Técnicas Seleccionadas.
Procedimiento realizado por fases, cada una de las mismas comprende un conjunto completo de pruebas a cada técnica seleccionada, para determinar cuáles son las variables independientes que mejor predicen la variable dependiente, con el propósito de encontrar un modelo predictivo que solucione el problema de la presente investigación.
Los resultados de cada prueba son tabulados en una tabla y representados gráficamente, se hace de las dos formas porque se complementan, debido que cada representación aporta valores agregados a la investigación. La tabla refleja el valor exacto de cada indicador, entre tanto, la gráfica muestra el valor aproximado de cada indicador y su valor mínimo requerido en la investigación.
Tabla 4.13. Variables de entrada para las pruebas de la fase N° 1.
Independientes | codigo, dpto, prioridad, fecha | ||
Dependiente | cantidad | ||
Tabla 4.14. Prueba N° 1. Fase N° 1. Técnica clustering.

Tabla 4.15. Prueba N° 2. Fase N° 1. Técnica J48.

Tabla 4.16. Prueba N° 3. Fase N° 1. Técnica JRip.

Tabla 4.17. Prueba N° 4. Fase N° 1. Técnica Naïve Bayes.

Tabla 4.18. Prueba N° 5. Fase N° 1. Técnica OneR.

Tabla 4.19. Prueba N° 6. Fase N° 1. Técnica perceptrón multicapa.

Tabla 4.20. Prueba N° 7. Fase N° 1. Técnica REPTree.

Tabla 4.21. Variables de entrada para las pruebas de la fase N° 2.
Independientes | costo, prioridad, refrigerado, almacenaje, fecha | ||
Dependiente | cantidad | ||
Tabla 4.22. Prueba N° 1. Fase N° 2. Técnica clustering.

Tabla 4.23. Prueba N° 2. Fase N° 2. Técnica J48.

Tabla 4.24. Prueba N° 3. Fase N° 2. Técnica JRip.

Tabla 4.25. Prueba N° 4. Fase N° 2. Técnica Naïve Bayes.

Tabla 4.26. Prueba N° 5. Fase N° 2. Técnica OneR.

Tabla 4.27. Prueba N° 6. Fase N° 2. Técnica perceptrón multicapa.

Tabla 4.28. Prueba N° 7. Fase N° 2. Técnica REPTree.

Tabla 4.29. Variables de entrada para las pruebas de la fase N° 3.
Independientes | codigo, dpto, costo, stockMin, stockMax, prioridad, refrigerado, almacenaje, fecha | ||
Dependiente | cantidad | ||
Tabla 4.30. Prueba N° 1. Fase N° 3. Técnica clustering.

Tabla 4.31. Prueba N° 2. Fase N° 3. Técnica J48.

Tabla 4.32. Prueba N° 3. Fase N° 3. Técnica JRip.

Tabla 4.33. Prueba N° 4. Fase N° 3. Técnica Naïve Bayes.

Tabla 4.34. Prueba N° 5. Fase N° 3. Técnica OneR.

Tabla 4.35. Prueba N° 6. Fase N° 3. Técnica perceptrón multicapa.

Tabla 4.36. Prueba N° 7. Fase N° 3. Técnica REPTree.

Cierre: Para finalizar la etapa de selección y aplicación de algoritmos de minería de datos, en la siguiente tabla se detallan los modelos candidatos para la solución del problema, que cumplen con los requerimientos de la investigación.
Tabla 4.37. Matriz pruebas de validación a las técnicas seleccionadas.

4.5. Interpretación y Evaluación de los Patrones Encontrados.
Tabla 4.38. Relación entre los modelos encontrados.

Fuente: Software Weka.
Relación de las Variables.
Procedimiento a través del cual utilizando diagramas de dispersión y la tabla de coeficientes de correlación, se analizan visualmente las variables utilizadas por las técnicas para construir los modelos respecto a la variable dependiente. Estudio que se realiza con el propósito de conseguir factores determinantes que aumenten la efectividad de los modelos.

Figura 4.1. Diagrama de dispersión, X = codigo, Y = cantidad.
Fuente: Software Weka.

Figura 4.2. Diagrama de dispersión, X = dpto, Y = cantidad.
Fuente: Software Weka.

Figura 4.3. Diagrama de dispersión, X = costo, Y = cantidad.
Fuente: Software Weka.

Figura 4.4. Diagrama de dispersión, X = stockMin, Y = cantidad.
Fuente: Software Weka.

Figura 4.5. Diagrama de dispersión, X = stockMax, Y = cantidad.
Fuente: Software Weka.

Figura 4.6. Diagrama de dispersión, X = prioridad, Y = cantidad.
Fuente: Software Weka.
Tabla 4.39. Coeficiente de correlación entre las variables.

Fuente: Software Weka.
Análisis de los Diagramas de Dispersión y el Coeficiente de Correlación.
Luego de observar cada diagrama de dispersión y la tabla de coeficiente de correlación entre variables, haciendo especial énfasis donde se muestra la relación entre stockMax y cantidad, por ser el stockMax la única variable independiente que coincidieron en emplear las dos técnicas de minería de datos para construir el modelo predictivo y la cantidad la variable dependiente o variable a predecir. Situación confirmada por el coeficiente de correlación, debido que el stockMax y la cantidad presentan la mejor relación entre variables, con un índice de dependencia positivo casi perfecto.
En el diagrama de dispersión del stockMax y la cantidad (Figura 4.5.) se observa que algunos pocos puntos que representa la cantidad, despliegan una significativa dispersión con respecto al stockMax. En relación a lo expuesto y con el propósito de mejorar los resultados de los modelos, se realizan los siguientes procedimientos y análisis denominados pruebas de la fase 4.
1. Realizar la selección de atributos que ofrece Weka, al conjunto de variables de entrada.
2. Modificar la discretización de la variable dependiente cantidad, la primera discretización se realizó en la etapa de transformación de los datos, quedando conformada por grupos múltiplos de 5, y con la cual se realizaron las pruebas de las fases N° 1, 2 y 3. Se modifica la discretización a grupos múltiplos de 2, para las pruebas de la fase N° 4. Con el objetivo de analizar el comportamiento de los modelos en estudio.
3. Mediante el uso del lenguaje de programación PHP, se realiza una búsqueda y reemplazo de los valores con mayor dispersión de la variable cantidad, observados en el diagrama de dispersión stockMax y cantidad, por valores promedios.
4. Realizar regresión lineal de forma individual a cada variable independiente respecto con la variable dependiente, para comprobar las relaciones deterministas en la construcción del modelo.
5. Modificar las opciones que ofrece Weka, para las técnicas J48 y OneR, en la construcción de los modelos en estudio, para analizar su tendencia.
Tabla 4.40. Prueba Nº 1. Fase Nº 4.

Tabla 4.41. Prueba N° 2. Fase N° 4.

Tabla 4.42. Prueba N° 3. Fase N° 4.

Tabla 4.43. Prueba N° 4. Fase N° 4.

Tabla 4.44. Prueba N° 5. Fase N° 4. Técnica J48.

Tabla 4.45. Prueba N° 6. Fase N° 4. Técnica OneR.

Optimizando los Modelos Encontrados.
Luego de realizar las pruebas de la fase Nº 4, se procedió a modificar el conjunto de opciones que ofrecen mejores resultados a cada técnica, para determinar el total del rendimiento de cada modelo. Los resultados se detallan en la siguiente tabla.
Tabla 4.46. Resultados luego de las pruebas de la fase N° 4.

Atendiendo las consideraciones anteriores, se establece positiva la hipótesis de la investigación, en consecuencia, si es posible obtener un modelo predictivo para la gestión de insumos y medicamentos, a partir de los datos históricos disponibles en la base de datos del sistema SAISYS del Hospital General de Táriba, mediante el uso de técnicas de minería de datos.
Tabla 4.47. Descripción del modelo predictivo definitivo encontrado.

Fuente: Software Weka.
4.6. Desarrollo de la Herramienta Informática para Consultar el Modelo Predictivo Encontrado
El desarrollo de la herramienta informática se inició a partir de las reglas generadas por Weka a través del modelo predictivo J48 encontrado. Se construyeron dos librerías una de tipo JavaScript y otra de tipo PHP, se realizaron de esa forma para tener el modelo disponible en dos formatos, básicamente cada librería contiene una función que recibe como parámetros las variables stockMax y fecha, para luego aplicar las reglas del modelo y retornar el valor predictivo de la cantidad. Las librerías se sometieron a diferentes pruebas para confirmar la veracidad de sus resultados, después de comprobar que proporcionaban información 100% fidedigna, se aprobaron como aptas para la siguiente etapa del proceso.
Finalmente utilizando la librería PHP del modelo J48 y empleando la metodología RAD (Desarrollo rápido de aplicaciones) se procedió a desarrollar en el lenguaje de programación PHP, la herramienta informática que consulta el modelo encontrado, y por consiguiente, apoya en la toma de decisiones para la gestión de insumos y medicamentos en el Hospital General de Táriba. La cual ofrece las características que se especifican en la siguiente tabla, posteriormente se presenta las figuras con las principales pantallas y reportes que genera la herramienta informática.
Tabla 4.48. Lista de cotejo. Descripción de la herramienta informática.


Figura 4.7. Pantalla iniciar sesión.

Figura 4.8. Pantalla inicio de la herramienta informática.

Figura 4.9. Pantalla predecir individual.

Figura 4.10. Pantalla predecir categorizada.

Figura 4.11. Pantalla predecir general.

Figura 4.12. Pantalla estadística individual.

Figura 4.13. Pantalla estadística por fecha.

Figura 4.14. Pantalla estadística en histogramas.

Figura 4.15. Pantalla actualización de usuarios.

Figura 4.16. Reporte predicción de consumo mensual categorizada.

Figura 4.17. Reporte predicción de consumo mensual general.

Figura 4.18. Reporte estadística de consumo mensual.
CAPÍTULO V
Conclusiones y recomendaciones
5.1. Conclusiones.
El estudio se originó a través de una investigación proyectiva dentro del contexto de la inteligencia de negocios a través de la minería de datos, con el objetivo de construir un modelo predictivo para la gestión de insumos y medicamentos en el Hospital General de Táriba. Siguiendo el proceso KDD se realizó la selección, integración, preparación y transformación de los datos, selección y aplicación de algoritmos de minería de datos, interpretación y evaluación de los patrones encontrados.
Las técnicas seleccionadas para realizar el análisis fueron las siguientes: Clustering, J48, JRip, Naïve Bayes, OneR, perceptrón multicapa y REPTree. Los requerimientos establecidos en la investigación para elegir un modelo como aprobado para la solución de la problemática planteada, se establecieron de la siguiente forma: Clasificación correcta superior al 75% y estadística kappa mayor al 0,75 de fuerza de concordancia.
La investigación del modelo origino que la variable que mejor define la predicción de las cantidades de insumos y medicamentos, es la variable stockMax la cual contiene la máxima provisión de cada producto, sus valores son numéricos no continuos que fluctúan entre 0 y 36.000. La afirmación de mejor definición se fundamenta en el diagrama de dispersión (Figura 4.5.) y el coeficiente de correlación (Tabla 4.39.), donde la variable stockMax presenta la mejor relación entre variables. No obstante las demás variables independientes utilizadas como entrada, mejoran el rendimiento del modelo encontrado.
El proceso investigativo se realizó con una variable dependiente o de predicción (cantidad), la cual para las pruebas de las fases Nº 1, 2 y 3 se utilizó con valores discretos múltiplos de 5, y para las pruebas de la fase Nº 4 se empleó con valores discretos múltiplos de 2, con el objetivo de ofrecer mayor confiabilidad al modelo elegido para desarrollar la herramienta informática.
Durante la investigación se determinó que el proceso de realizar la búsqueda y reemplazo de los valores con mayor dispersión de la variable cantidad, aporto el mejor resultado en el rendimiento de los modelos predictivos en cada técnica de minería de datos, con un aumento del 14,68% de la clasificación correcta en el modelo J48. Otra técnica que generó aporte positivo en los modelos consistió en la modificación de las opciones que ofrece Weka, para la técnica J48 generó un aumento en el rendimiento del modelo encontrado de 0,97%.
Las técnicas de minería de datos orientados a modelos predictivos J48 y OneR, aportaron las soluciones más óptimas al problema, de todas las técnicas analizadas en la investigación. Siendo el modelo construido por la técnica árbol de decisión J48 el que mejor porcentaje presento para predecir, con una clasificación correcta de 91,20% y una estadística kappa 0,9006 de fuerza de concordancia, se eligió como modelo para desarrollar la herramienta informática.
El desarrollo del estudio comprobó que por medio del software Weka, se pueden construir, probar y validar modelos de minería de datos de una manera rápida y confiable, a través de la amplia variedad de algoritmos y opciones de minería de datos que ofrece la mencionada herramienta. Contexto determinante en la obtención del modelo para la solución del problema de la presente investigación, y por consiguiente, establecer como positiva la hipótesis de la investigación.
La herramienta informática producto del modelo encontrado, ofrece múltiples consultas y reportes predictivos que sirven de soporte para la toma de decisiones en cuanto a la gestión de los insumos y medicamentos en el Hospital General de Táriba. La información generada por medio de la herramienta informática es en relación al patrón de consumo de las áreas de la institución, en consecuencia, sus principales logros son la optimización de los recursos y el bienestar social tanto para el hospital como para sus usuarios.
5.2. Recomendaciones.
Se recomienda principalmente seguir tres líneas de acción, la primera línea consiste en realizar estudios para buscar nuevas variables, mientras tanto, la segunda línea de trabajo comprende efectuar pruebas con otras técnicas de minería de datos, por último, la tercera línea de acción está dirigida a emplear herramientas para el descubrimiento de conocimiento o proceso de minería de datos diferentes a Weka, como SQL Server Business Intelligence Development. Lo antes expuesto, se recomienda como trabajos futuros con el objetivo de realizar comparación de resultados o para mejorar el rendimiento del modelo encontrado en la presente investigación.
Referencias bibliográficas
LIBROS
Bernal T., César A. (2010). Metodología de la investigación. (3ra ed.). Colombia: Pearson Educación.
Hernández S., Fernández C. y Baptista P. (2010). Metodología de la investigación. (5ta ed.). México: Mc Graw Hill.
Tamayo y T., M. (2010). El proceso de la investigación científica. (4ta ed.). México: Limusa.
TRABAJOS ACADÉMICOS
Trabajos de grado y tesis doctorales
Sánchez R., J. (2010). Sistema web para diagnóstico de enfermedades prevalentes en la infancia mediante técnicas de minería de datos y aprendizaje automático. Universidad Nacional Experimental del Táchira, San Cristóbal.
Documentos y reportes técnicos
Hospital General de Táriba. (2015). Manual Organizacional. Táriba. Autor.
Documentos de tipo legal
Constitución de la República Bolivariana de Venezuela. (2000). Gaceta Oficial de la República Bolivariana de Venezuela No 5.453 (Extraordinaria). Marzo 24, 2000.
Decreto Nº 1.399, con Rango, Valor y Fuerza de Ley de Contrataciones Públicas. (2014). Gaceta Oficial de la República Bolivariana de Venezuela Nº 6.154 (Extraordinaria). Noviembre 19, 2014.
Decreto Nº 1.798. (1983). Gaceta Oficial de la República de Venezuela Nº 32.650. Enero 21, 1983.
Ley de Infogobierno. (2013). Gaceta Oficial de la República Bolivariana de Venezuela No 40.274. Octubre 17, 2013.
Ley Orgánica de la Administración Pública. Decreto N° 6.217. (2008). Gaceta Oficial de la República Bolivariana de Venezuela No 5.890 (Extraordinaria). Julio 31, 2008.
FUENTES ELECTRÓNICAS
Tesis en línea
Aldas, L. (2013). Sistema web para el control de facturación e inventario de medicamentos y bienes en el Hospital Regional Docente Ambato. Universidad Técnica de Ambato, Ecuador. Consultada el 18 de noviembre de 2014 en: http://repo.uta.edu.ec/bitstream/handle/123456789/6249/Tesis_t853si.pdf?sequence=1
Arias, J. (2012). Diseño y construcción de un data mart para el filtro de opiniones en la web a partir de datos originados en el portal educar Chile. Universidad de Chile, Santiago de Chile. Consultada el 26 de noviembre de 2014 en: http://tesis.uchile.cl/bitstream/handle/2250/111296/cf-arias_jc.pdf?sequence=1
Bayter, A. (2008). Mejoramiento en la gestión de compras e inventario de medicamentos y dispositivos médicos en la Clínica Prevención y Salud IPS LTDA, en el Banco Magdalena. Universidad Industrial de Santander, Bucaramanga Colombia. Consultada el 18 de noviembre de 2015 en: http://www.ddic.com.mx/investigacion/wp-content/uploads/2013/10/busatamante2008tesis.pdf
Corso, C. (2009). Aplicación de algoritmos de clasificación supervisada usando Weka. Universidad Tecnológica Nacional, Facultad Regional Córdoba. Argentina. Consultada el 7 de marzo de 2016 en: http://www.investigacion.frc.utn.edu.ar/labsis/Publicaciones/congresos_labsis/cynthia/CNIT_2009_Aplicacion_Algoritmos_Weka.pdf
Gonzales, R. (2012). Impactó de la data warehouse e inteligencia de negocios en el desempeño de las empresas: investigación empírica en Perú, como país en vías de desarrollo. Universitat Ramón Llull. Consultada el 25 de noviembre de 2014 en: http://www.tesisenred.net/bitstream/handle/10803/85876/GONZALES_Tesis Doctoral_FV.pdf?sequence=1
Guillén, F. (2012). Desarrollo de un datamart para mejorar la toma de decisiones en el área de tesorería de la Municipalidad Provincial de Cajamarca. Universidad Privada del Norte, Perú. Consultada el 14 de enero de 2015 en: http://repositorio.upn.edu.pe/handle/upnorte/123
Martínez, C. (2012). Aplicación de técnicas de minería de datos para mejorar el proceso de control de gestión en Entel. Universidad de Chile, Santiago de Chile. Consultada el 14 de enero de 2015 en: http://www.tesis.uchile.cl/bitstream/handle/2250/112065/cf-martinez_ca.pdf?sequence=1
Recasens, J. (2011). Inteligencia de negocios y automatización en la gestión de puntos y fuerza de ventas en una empresa de tecnología. Universidad de Chile, Santiago de Chile. Consultada el 25 de noviembre de 2014 en: http://www.tesis.uchile.cl/tesis/uchile/2011/cf-recasens_js/html/index-frames.html
Vielma, I. (2013). Mejoramiento de la gestión de insumos de pabellón del Hospital Exequiel González Cortés. Universidad de Chile, Santiago de Chile. Consultada el 20 de enero de 2015 en: file:///C:/Documents and Settings/Almac%C3%A9n/Mis documentos/Downloads/cf-vielma_ig.pdf
Artículo de revista electrónica
Hernández, M. (2011). Procedimiento para el desarrollo de un sistema de inteligencia de negocios en la gestión de ensayos clínicos en el Centro de Inmunología Molecular. ACIMED, 22(4), 349–361. Consultada el 18 de noviembre de 2014 en: http://scielo.sld.cu/scielo.php?script=sci_arttext&pid=S1024-94352011000400006
Hernández, T. (2010). Acciones sobre los determinantes sociales de la salud en Venezuela. Revista Cubana de Salud Pública, 36(4), 366–371. Consultada el 10 de agosto de 2015 en: http://scielo.sld.cu/pdf/rcsp/v36n4/spu13410.pdf
Landis, J. Koch, G. (1977). The measurement of observer agreement for categorical data. Biometrics, 33(1), 159-174. Consultada el 28 de marzo de 2015 en: http://www.jstor.org/stable/2529310
Rodríguez, Y., y Díaz, A. (2009). Herramientas de minería de datos. Revista Cubana de Ciencias Informáticas, 3(3), 73–80. Consultada el 20 de enero de 2015 en: https://rcci.uci.cu/index.php/rcci/article/view/78/70
Soria, J., y Mamani, G. (2013). Modelo de simulación de inventario basado en redes neuronales artificiales supervisadas y algoritmos genéticos para optimizar el stock de medicamentos de la Clínica Ricardo Palma. INGETECNO, 2(1). Consultada el 15 de enero de 2015 en: file:///C:/Documents and Settings/Almac%C3%A9n/Mis documentos/Downloads/176-552-1-PB (2).pdf
Anexos
1. Clasificación de los listados por tipo de producto.
Ítem | Descripción | ||
1 | Material médico. | ||
2 | Medicamentos. | ||
3 | Insumos para laboratorio. | ||
4 | Insumos para odontología. | ||
5 | Insumos para radiología. | ||
6 | Insumos para nutrición y dietética. | ||
7 | Útiles de escritorio y oficina. | ||
8 | Materiales para mantenimiento y usos generales. | ||
9 | Insumos para limpieza y aseo. | ||
10 | Instrumental. | ||
2. Sistema Actual SAISYS.


3. Estructura de la Base de Datos Actual.
Tabla maestro.
Id | Nombre | Descripción | Observaciones | ||||||||||||
1 | CODIMAE | Código del artículo. | |||||||||||||
2 | DESCRIP | Descripción del artículo. | |||||||||||||
3 | REFEREN | Referencia. | Mayoría tiene "001" | ||||||||||||
4 | DEPARTA | Departamento. | |||||||||||||
5 | UNIDAD | Presentación. | |||||||||||||
6 | CANTUNI | Cantidad por unidad. | Todos tiene "1" | ||||||||||||
7 | EXISTE | Existencia. | |||||||||||||
8 | PVP1 | Precio1. | Ultimo costo. | ||||||||||||
9 | PVP2 | Precio2. | Ultimo costo. | ||||||||||||
10 | PVP3 | Precio3. | No tiene datos. | ||||||||||||
11 | PVP4 | Precio4. | No tiene datos. | ||||||||||||
12 | COSTO | Costo. | |||||||||||||
13 | ULTICOST | Ultimo costo. | |||||||||||||
14 | STOCK | Mínima provisión. | |||||||||||||
15 | FVENTA | Fecha de venta. | |||||||||||||
16 | FCOMPRA | Fecha de compra. | |||||||||||||
17 | PROVEE1 | Proveeedor1. | No tiene datos. | ||||||||||||
18 | PROVEE2 | Proveeedor2. | No tiene datos. | ||||||||||||
19 | UBICA | Ubicación. | No tiene datos. | ||||||||||||
20 | AUDITO | Auditoria. | |||||||||||||
21 | STATUS | Status. | Todos tienen "1" | ||||||||||||
22 | EXISINIC | Existencia inicial. | No tiene datos. | ||||||||||||
23 | FECHINIC | Fecha inicial. | |||||||||||||
24 | IVA | Impuesto. | |||||||||||||
25 | LABORAB | Laboratorio. | No tiene datos. | ||||||||||||
26 | PESOB | Peso. | No tiene datos. | ||||||||||||
27 | CODIREP | Código del repuesto. | No tiene datos. | ||||||||||||
28 | REEMPLA1 | Reemplazo 1. | No tiene datos. | ||||||||||||
29 | REEMPLA2 | Reemplazo 2. | No tiene datos. | ||||||||||||
30 | GRUPO | Grupo. | |||||||||||||
31 | MARCA_REP | Marce del repuesto. | No tiene datos. | ||||||||||||
32 | MARCA_VEH | Marca del vehículo. | No tiene datos. | ||||||||||||
33 | MODELO_VEH | Modelo del vehículo. | No tiene datos. | ||||||||||||
34 | MOTOR | Motor de vehículo. | No tiene datos. | ||||||||||||
35 | FACTCOMP | Factura de compra. | No tiene datos. | ||||||||||||
36 | STOCKMA | Máxima provisión. | |||||||||||||
37 | VENCIMI | Vencimiento. | No tiene datos. | ||||||||||||
38 | CODICONT | Código continúo. | No tiene datos. | ||||||||||||
Tabla transaccional.
Id | Nombre | Descripción | Observaciones | ||||||||||||
1 | CORRGENE | Correlativo generado. | |||||||||||||
2 | STATTRAN | Estatus de la transacción. | Blanco – 1 – 2 | ||||||||||||
3 | TIPOTRAN | Tipo de transacción. | 1 – 2 – 9 | ||||||||||||
4 | CODITRAN | Código de la transacción. | Código del producto. | ||||||||||||
5 | STATBUSQ | Estatus de búsqueda. | No tiene datos. | ||||||||||||
6 | FECHTRAN | Fecha de la transacción. | |||||||||||||
7 | CANTTRAN | Cantidad de la transacción. | |||||||||||||
8 | PVP_TRAN | Precio de venta al público de la transacción. | Costo. | ||||||||||||
9 | COSTTRAN | Costo de la transacción. | CANTTRAN x PVP_TRAN | ||||||||||||
10 | COPRTRAN | Costo promedio de la transacción. | COSTTRAN / CANTTRAN | ||||||||||||
11 | DESCTRAN | Descuento de la transacción. | No tiene datos. | ||||||||||||
12 | EXISTRAN | Existencia del artículo. | |||||||||||||
13 | CORRFACT | Correlativo de la factura. | |||||||||||||
14 | NOENTRAN | Número de entrada. | No tiene datos. | ||||||||||||
15 | FACTTRAN | Factura de la transacción. | |||||||||||||
16 | NUMETRAN | Número de la transacción. | |||||||||||||
17 | CODIVEND | Código del vendedor. | Blanco – Código del servicio de destino. | ||||||||||||
18 | CODICLIE | Código del cliente. | No tiene datos. | ||||||||||||
19 | IMPUTRAN | Imputación de la transacción. | |||||||||||||
20 | ISV_TRAN | IVA de la transacción. | |||||||||||||
21 | CODIDESP | Código de despacho. | No tiene datos. | ||||||||||||
22 | VENCIMI | Vencimiento del producto. | No tiene datos. | ||||||||||||
4. Solicitud de Compra Actual.


DEDICATORIA
A mi madre María Gladys Rodríguez de Zambrano, por sus años de lucha, su infinito amor, sus sabios consejos. Mis logros en la vida se los debo a mi madre, siempre vivirás en mi mente y corazón.
Te Amo Mamá.
RECONOCIMIENTOS
A Dios, por sus eternas bendiciones.
A mi padre Pablo Alfonso Zambrano Cuervo, por ser un excelente ser humano.
A mis hijas Heliany Yineth y María Fernanda, por representar los amores de mi vida.
A mi tutor MSc. Marcel Molina, por su apoyo y orientación.
Al Hospital General de Táriba, por su significativa colaboración.
A la Universidad Nacional Experimental del Táchira (UNET). En especial a los profesores que me impartieron clases, por su extraordinario profesionalismo.
Autor:
Zambrano Rodríguez, Hernán Alfonso.
Tutor: Molina Monsalve, Marcel Mauricio.

Universidad Nacional Experimental del Táchira
Vice-Rectorado Académico
Decanato de Postgrado
Maestría en Informática
Trabajo de Grado, presentado como requisito para optar al Título de Magíster en Informática.
San Cristóbal, Junio de 2.016
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |